
Saga Patterns in Kalix Part 5 - Orchestration with Workflows
- Andrzej Ludwikowski.
- Software Architect, Lightbend.
- 1 Sept 2023,
- 7 minute read
In the first four parts of this series, we examined choreography-based Sagas. In this last installment, we will cover the second Saga flavor - orchestration. This time the solution will be more request-driven compared to the event-driven choreography, but that doesn’t mean you can’t mix the two approaches together. More on that below.
The Kalix ecosystem has a dedicated component called Workflow for business process orchestration. The plan for this part of the series is to rewrite the seat reservation process into a workflow-based Saga. I will not repeat the basics of the Workflow component, which are already described in the Introducing Kailx Workflows blog post. It’s better to focus more on the challenges of orchestration-based Sagas in general and in the context of Kalix.
Seat reservation workflow
Just to recap, our workflow process has three main steps:
- seat reservation
- wallet charge
- reservation confirmation.
Technically speaking, the last step is not mandatory in the orchestration-based solution. With a different domain model, we could remove it. Since we are reusing the same domain from the choreography-based implementation, we will support it. It won’t change the overall solution too much.
var reserveSeat = step(RESERVE_SEAT_STEP)
.call(this::reserveSeat)
.andThen(Response.class, this::chargeWalletOrStop);
var chargeWallet = step(CHARGE_WALLET_STEP)
.call(this::chargeWallet)
.andThen(Response.class, this::confirmOrCancelReservation);
var confirmReservation = step(CONFIRM_RESERVATION_STEP)
.call(this::confirmReservation)
.andThen(Response.class, this::endAsCompleted);Any step can fail, but each type of failure requires a different strategy. Let’s start by grouping failures into two main categories:
- business failures
- infrastructure failures.
Each known business failure should be handled explicitly. A good example can be a wallet charge request. If the response from the WalletEntity is a Failure (e.g. insufficient funds), we can immediately launch the compensation and cancel the reservation. In a real-world scenario, the response type should be verbose enough to easily choose the next step. Most likely having only two options Failure and Success won't be enough to cover all possibilities.
private TransitionalEffect<Void> confirmOrCancelReservation(Response response) {
return switch (response) {
case Response.Failure failure -> {
yield effects()
.updateState(currentState().asWalletChargeRejected())
.transitionTo(CANCEL_RESERVATION_STEP);
}
case Response.Success __ -> effects()
.updateState(currentState().asWalletCharged())
.transitionTo(CONFIRM_RESERVATION_STEP);
};
}Infrastructure failures are more tricky. In the case of a time-out exception from the WalletEntity we don’t know if the wallet was actually charged or not. The first line of defense should be a retry mechanism. Maybe it was just a temporary glitch, after a few attempts the WalletEntity might be healthy again and respond with some data.
An obvious conclusion is that all workflow step actions should beidempotent, we already know how to achieve this with a proper deduplication strategy described in part 3 of the series.
If the infrastructure failure is permanent, we should stop retrying and tell Kalix what our compensation step is.
workflow()
…
.addStep(chargeWallet, maxRetries(3).failoverTo(REFUND_STEP))Compensation steps are like any other steps.
var cancelReservation = step(CANCEL_RESERVATION_STEP)
.call(this::cancelReservation)
.andThen(Response.class, this::endAsFailed);
var refund = step(REFUND_STEP)
.call(this::refund)
.andThen(Response.class, this::cancelReservation);It’s our responsibility to keep track of what should be compensated after each workflow step. That’s why the workflow state SeatReservation not only stores data required to run workflow steps, but is also a state machine that reflects the progress of the business process.
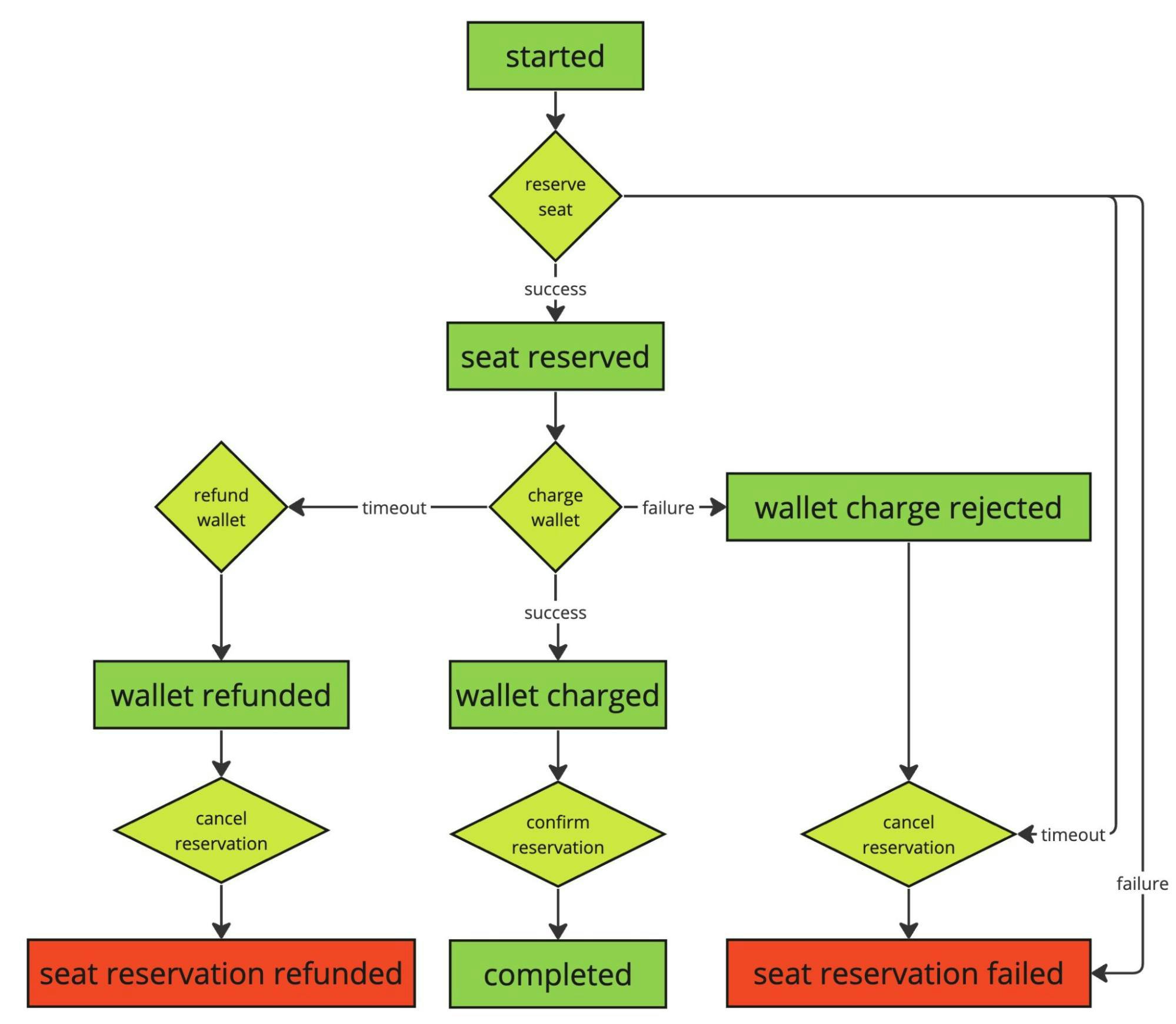
After refunding we also need to cancel the reservation. Other workflow solutions might automatically compensate all recorded steps, which binds step and compensation very tightly together.
In Kalix the developer has more freedom. It’s fine to compensate in the workflow with just one step. In the case of workflows with step loops, you don’t have to apply exactly the same number of compensations to recover the system.
One of the major challenges with compensation implementations is that they should be:
- idempotent (like any other step action)
- commutative
- and possibly infallible
Commutativity requires special attention. Compensation steps should be applicable in any order. If the WalletEntity is not responsive to the charge call, it will, most likely, be the same for the refund call. This is problematic because the seat remains reserved. From the business perspective, it’s better to cancel the reservation first and then do (or try to do) the refund. The seat will become available again for other users.
Switching the order in the current implementation might be a good homework exercise for the reader.
That’s not all. A step call and corresponding compensation should be commutative between each other. In other words, our implementation should cover the situation where a refund comes before the actual charge. This itself deserves a separate blog post, but in the context of the Kalix Workflow component and the underlying implementation of the Kalix Event Sourced Entity, we can assume that the refund will not surpass the charge operation (with a reasonable timeout). That might not be the case when calling external systems.
After the timeout, we actually don’t know if the charge operation was successful or not, which brings us to the last property of the compensation action - infallibility. The refund implementation should take into consideration that the wallet may never be charged. An expenses map Map<String, Expense> in our wallet domain could be a basic solution.
private Either<WalletCommandError, WalletEvent> handleRefund(Refund refund) {
return expenses.get(refund.expenseId()).fold(
() -> left(EXPENSE_NOT_EXISTS),
expense -> right(new WalletRefunded(id, expense.amount(), expense.expenseId(), refund.commandId()))
);
}The expenses collection will grow with time, so make sure that you apply some restrictions to it. Similar to the
commandIds set, used for deduplication.The EXPENSE_NOT_EXISTS error will later be translated into a successful response from the WalletEntity.
Some step definitions may also try to be infallible. There is no point in creating compensation for the seat reservation confirmation step. A failure at this point is most likely a bug in the code and the only thing we can do is to apply a generic failover strategy for the entire workflow. This could be an additional state machine end state that requires manual intervention by a system administrator.
Summary
In the previous implementation (choreography-based) we used six Kalix components, five Actions and one View to implement our business process. All of this is replaced by one Workflow component. Does this mean that the Workflow is a replacement for event-driven choreography? Certainly not. Each solution has its own very specific advantages and disadvantages.
Choreography-based Saga
- Positives:
- loose coupling: no central coordination, no single point of failure, each service operates independently and asynchronously.
- evolution: keeping the published event contract stable might be easier than with a rapidly evolving synchronous API.
- scalability: asynchronous communication is often more efficient and scalable than synchronous communication.
- Negatives:
- complexity: choreography-based flow can spread over too many services making it hard to follow and understand. It’s difficult to get a holistic view of the system.
- no central control: hard to monitor the dependencies between services and business process failures.
- troubleshooting: in case of failure it’s more problematic to track and debug a single chain of events.
Orchestration-based Saga
- Positives:
- centralized control: easier to monitor and manage the interactions between the microservices, as well as understand the overall process.
- troubleshooting: a central coordinator allows for easier failure tracking and debugging.
- Negatives:
- coupling: tighter coupling makes the system less scalable and resilient.
- single point of failure: the central coordinator can be a single point of failure, stopping this service will stop the processing (Kalix Workflows are guaranteed to run to completion).
- overhead: event-driven pipelines are usually characterized as more performant and less resource-demanding than synchronous calls from the coordinator.
- evolution: in some cases, special strategies must be applied when deploying a new process version.
An interesting observation is that some pros are cons (and vice versa), depending on the context. Centralized vs decentralized processing. High coupling vs loose coupling. There is no winner in this battle.
Since it's very easy to use both in Kalix, we should choose the best solution for a given problem. The full potential can be unleashed when we combine both solutions together. For a Dead Letter Queue implementation from the fourth part we could use a Workflow. And then fast asynchronous event processing for the green path joins forces with synchronous processing for failure situations. On the other hand, some workflow steps can be triggered by Actions that subscribe to entity events. This way, we can switch from synchronous to asynchronous communication. I should mention that we are also planning to add more built-in event-driven capabilities to the Kalix Workflows.
Thank you for reading this five part series on Saga Patterns in Kailx. I would recommend analyzing the full source code behind this chapter. Running SeatReservationWorkflowTest from the part5 tag might be a good starting point. It’s also possible to switch between different Saga implementations by passing an appropriate Spring profile: choreography or orchestration. Different components will be enabled for a given profile, but both solutions implement the same business flow.