
Reducing Complexity with Kalix
- Noah Barnes.
- Staff Site Reliability Engineer, Lightbend.
- 16 January 2024,
- 7 minute read
Introduction
Kalix has a dedicated team of site-reliability engineers (SREs) whose goal is to facilitate as close to zero-downtime operations as possible to satisfy customer SLAs. Keeping all your applications updated, backed up, and secure is critical to your business. Using Kalix, you don’t have to worry about it. Most of the time, our maintenance is performed in a manner that keeps Kalix applications running without interruption.
What’s a day in the life of a Kalix SRE like? Read on and see.
Kubernetes 1.21 to 1.22
In the last few months, we’ve upgraded Kubernetes from 1.21 to 1.25, so that the Kalix platform stays up-to-date with the latest features and security improvements. We had to upgrade Kubernetes with zero downtime, so lots of planning and testing went into it. If you have ever dealt with an application outage or an extended maintenance window, you know that making big changes to infrastructure without downtime is not easy.
We always test changes in our development and staging environments before attempting them in production. This lowers the risk of failure, as we already know what to expect since we’ve done it a few times before. We use infrastructure-as-code which helps avoid disparity across environments and minimizes human errors.
The upgrade from 1.21 to 1.22 involved updating several deprecated APIs, so first we had to update all of the resources within Kubernetes to use a 1.22 compatible API. While interacting with Kubernetes, warnings can sometimes be shown, especially if you are running a legacy version.
- rbac.authorization.k8s.io/v1beta1 ClusterRoleBinding is deprecated in v1.17+, unavailable in v1.22+; use rbac.authorization.k8s.io/v1 ClusterRoleBinding
- rbac.authorization.k8s.io/v1beta1 ClusterRole is deprecated in v1.17+, unavailable in v1.22+; use rbac.authorization.k8s.io/v1 ClusterRole
...
You can see that some resources were deprecated in 1.17 and will be removed completely in 1.22. Each one of these warnings must be addressed or that resource will fail to load. Once the resources have been updated and confirmed to be compatible with the correct version of Kubernetes, it is time to upgrade Kubernetes. Two components need to be updated, the control plane and the node pools where worker nodes live.
In a managed cloud environment, the control plane maintenance is managed by the cloud provider. To update it, you can simply increase the version number in a configuration file and the cloud provider handles doing a rolling upgrade. This upgrade process is behind-the-scenes from the cloud user’s perspective, but you can see the status of the upgrade as it progresses. Once that is complete, the control plane will be on 1.22 and the worker nodes will still be on 1.21. Next, we will need to update the worker nodes in the node pools.
The process is similar to the control plane but with the ability to control the process yourself. In our configuration, Kubernetes node pools are highly available across 3 availability zones. When the upgrade begins, it will spin up new nodes running 1.22 one at a time. For each new node that gets created, Kubernetes will cordon an old node making it unavailable for scheduling new workloads. After that, Kubernetes will begin draining those workloads that will be created on the new node. If the node is completely drained, then it gets deleted. The workload migration process gets cut over to the new node without causing an outage to the application. When all of the nodes are replaced, then the upgrade is complete.
We complete this process every time a new Kubernetes version is released, which is typically every 3-4 months.
Kubernetes 1.23-1.25
Less APIs were deprecated when upgrading from 1.23 to 1.25, so those upgrades were a lot easier. All of the steps above still had to occur. While these upgrades are streamlined and written as infrastructure as code, there is still quite a bit of testing and monitoring involved with each upgrade. For example, there was an Amazon EKS-specific change where action needed to be taken before we upgraded from 1.22 to 1.23. Here is the message we received in the console.
 Warning message displayed in the AWS console.
Warning message displayed in the AWS console.This driver was already installed in the cluster prior to 1.23, but beginning in version 1.23 it had to be explicitly installed, or anything depending on it would fail.
For the 1.25 upgrade, we encountered several different things being deprecated that required action on our part. Here are a few examples:
To learn more, consult https://cloud.google.com/blog/products/containers-kubernetes/kubectl-auth-changes-in-gke
Warning: batch/v1beta1 CronJob is deprecated in v1.21+, unavailable in v1.25+; use batch/v1 CronJob
Warning: policy/v1beta1 PodDisruptionBudget is deprecated in v1.21+, unavailable in v1.25+; use policy/v1 PodDisruptionBudget
If you are using PSP in your cluster, then before upgrading your cluster to version 1.25 you must migrate your PSP to the built-in Kubernetes Pod Security Standards or to a policy as code solution to avoid interruptions and protect your workloads.
Each one of these had to be addressed, and we also discovered some deprecated APIs that were being called so we had to update some running resources.
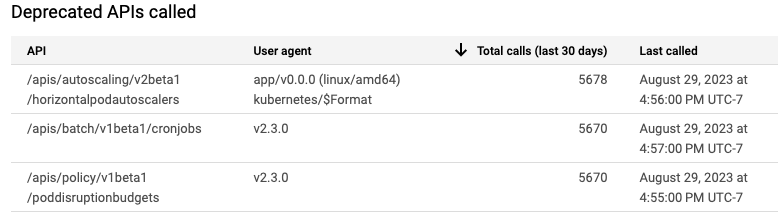
One of the many advantages of using Kalix is that our SREs can ensure that Kubernetes maintenance occurs behind the scenes for you. Kubernetes offers a lot of useful features, but you can get an idea of the complexities involved with keeping things up-to-date.
Database Maintenance
Kalix currently uses various database backends depending on the application use case. For this example, I will discuss upgrading one of our many database platforms, Amazon RDS. Some maintenance tasks will perform a rolling upgrade, which is not zero-downtime since connections get reset and the load balancer could try routing traffic to a restarting instance, however, it is minimal. Other maintenance tasks will cause an outage for a short period of time.
In Production, we use a multi-AZ installation which provides enhanced availability and durability of the database installation. During minor version upgrades, a multi-AZ deployment also minimizes downtime. When you perform a minor version upgrade of a Multi-AZ DB cluster, Amazon RDS upgrades the reader DB instances one at a time. Then, one of the reader DB instances switches to the new writer DB instance. Amazon RDS then upgrades the old writer instance (which is now a reader instance).
When performing major version upgrades, they may contain database changes that are not backward compatible with existing applications. Due to this, Amazon RDS does not install major version upgrades automatically. Therefore, you must manually modify your DB instance. During a major version upgrade, Amazon RDS simultaneously upgrades both the primary and standby replicas. The DB instance will not be available until the upgrade finishes. Currently, Amazon RDS does not yet support major version upgrades for Multi-AZ DB cluster deployments.
Thorough testing of the database is required before applying this type of upgrade to production instances. Although conducting maintenance is easier in a cloud-native environment, there are still configuration parameters, observability, maintenance planning, and thorough testing involved.
Choosing Kalix
Now you know a little bit about Kalix SREs and some advantages Kalix has to offer. For brevity, these two examples of regular maintenance do not include all the steps that have to be done behind the scenes. There are a lot more things we maintain regularly such as managing infrastructure lifecycle, CI/CD pipelines, security, observability, troubleshooting, database administration, etc, but this provides a taste. We would love to handle all of this complexity for you.
Conclusion
Kubernetes and database upgrades are always ongoing. If a Kubernetes version gets too far behind, then the cloud provider will forcefully upgrade the cluster which can cause an outage. We want to avoid this, so we are constantly checking for the latest updates and applying patches. There are a lot of moving pieces, deprecations, compatibility, security concerns, etc.
Every company has its own story about how they manage the complexity of technology. Using a PaaS like Kalix will allow your engineers to stay focused on writing business logic. This will reduce the need for SREs, DevOps Engineers, and Database Administrators to name a few. Costs will go down, and the time to market will increase. We would love to help your business achieve this, give Kalix a try for free.